IMPLEMENTASI APACHE SPARK PADA BIG DATA BERBASIS HADOOP DISTRIBUTED FILE SYSTEM
SEVIAN OLIVIANDI

Informasi Umum
Kode
18.04.213
Klasifikasi
C -
Jenis
Karya Ilmiah - Skripsi (S1) - Reference
Subjek
Big Data
Informasi Lainnya
Abstraksi
Big data merupakan kumpulan data dalam skala besar, yang mempunyai karakteristik data yang variatif, sangat cepat pertumbuhannya dan kompleks datanya. Data yang kompleks merupakan data yang tidak terstruktur yang perlu diolah khusus dengan suatu infrastruktur yang dapat mengelola data dalam volume besar. Pada tugas akhir ini digunakan metode MapReduce untuk memudahkan komputasi yang akan dilakukan pada suatu big data. MapReduce merupakan suatu model pemrograman untuk menulis aplikasi yang dapat memproses suatu big data secara paralel pada beberapa node. MapReduce memberikan kemampuan analitis untuk menganalisis volume besar data yang kompleks. Platform yang digunakan adalah Hadoop, Hadoop mempunyai algoritma MapReduce sendiri. Tugas akhir ini akan menganalisis performa dari Hadoop MapReduce dan membandingkannya dengan Apache Spark yaitu platform yang dibuat untuk memproses suatu big data yang dikembangkan berdasarkan Hadoop MapReduce dengan peningkatan performa pemrosesan. Skenario yang digunakan adalah memproses wordcount suatu data dengan besar data yang berbeda yang bertujuan untuk menganalisis response time dan penggunaan hardware dari kedua platform tersebut.
Kata kunci: Big Data, Apache Spark, MapReduce, Hadoop
- CEG3F3 - APLIKASI MOBILE
- SK3023 - ARSITEKTUR JARINGAN
- CEG3C3 - DESAIN BASIS DATA
- CEG2A3 - PEMROGRAMAN BERORIENTASI OBJEK
- CEG3E3 - SISTEM OPERASI
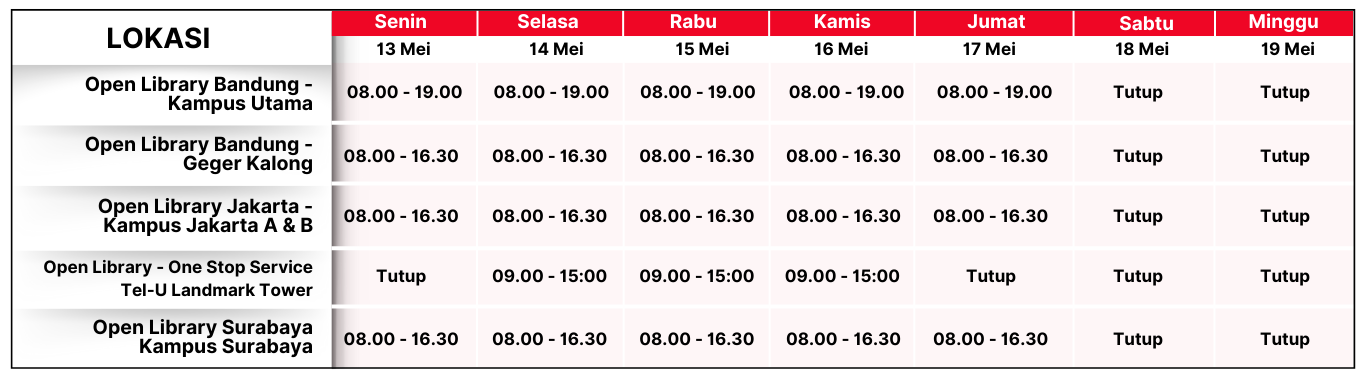
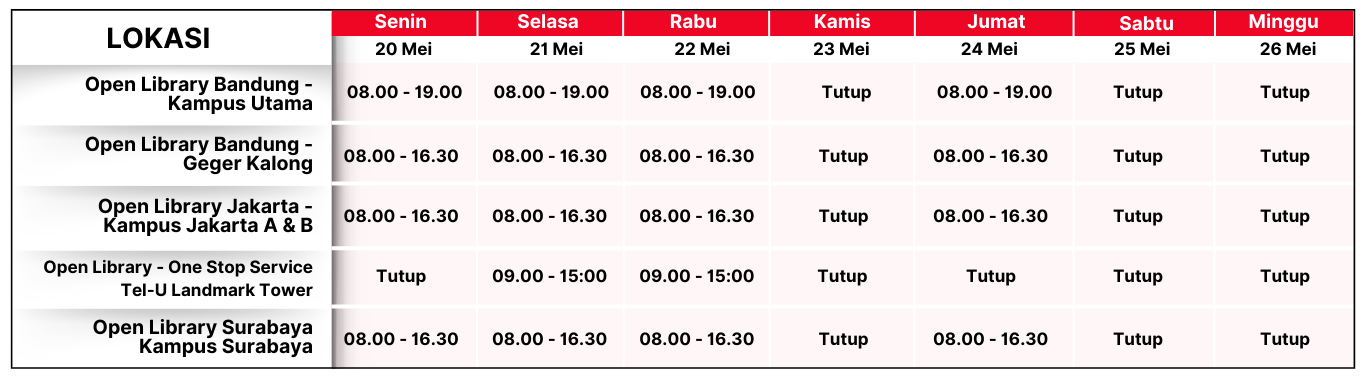
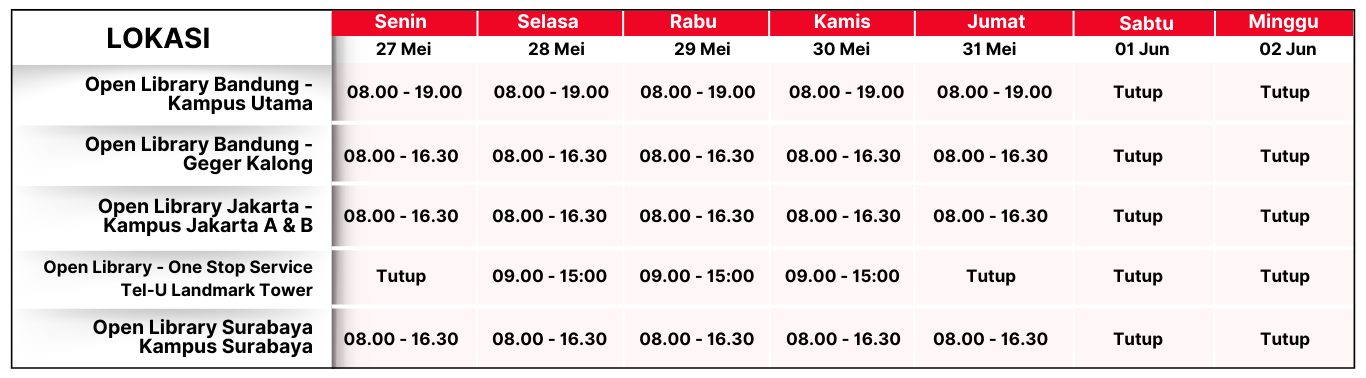
Koleksi & Sirkulasi
Seluruh 1 koleksi sedang dipinjam
Anda harus log in untuk mengakses flippingbook
Pengarang
| Nama | SEVIAN OLIVIANDI |
| Jenis | Perorangan |
| Penyunting | Andrew Brian Osmon |
| Penerjemah |
Penerbit
| Nama | Universitas Telkom, Sistem Komputer |
| Kota | Bandung |
| Tahun | 2018 |
Sirkulasi
| Harga sewa | IDR 0,00 |
| Denda harian | IDR 0,00 |
| Jenis | Non-Sirkulasi |